Large Language Models have become a new buzzword in the technology landscape. This powerful technology has transformed human interaction with computers and information, from chatbots to content creation tools.
This blog will explore everything about large language models (LLMs) that will enable you to understand this evolving landscape.
What are large language models (LLMs)?
A large language model, an LLM, is an artificial intelligence algorithm that uses deep learning techniques to perform natural language processing (NLP) tasks. These models are pre-trained using large datasets sequentially processed using a neural network architecture (a type of transformer model).
Neural networks are inspired by and created to mimic the workings of the human brain. They use interconnected nodes much like neurons in humans for data processing. Neural networks are also known as the building blocks of large language models. Training on massive datasets enables them to recognize, translate, predict, and generate text and content.
In addition to teaching these LLMs human languages, they can be trained to perform various other tasks, like writing code, creating content, and understanding complex information. The LLMs must be pre-trained and fine-tuned to get accurate results. The problem-solving abilities of large language models are useful in fields like manufacturing, healthcare, finance, and retail.
How do LLMs work?
Large language models are sophisticated AI systems that can understand and generate human-like text. As mentioned, they use deep learning and are trained on vast datasets. Here is the breakdown of how LLMs work:
Foundation in neural networks and deep learning
LLMs are created on neural networks, a type of transformer model. They consist of multiple layers of interconnected nodes to process information. Deep learning, part of machine learning, enables LLMs to learn complex patterns from the data using layers without human interference.
Transformer architecture
It is an essential aspect of LLMs that can process entire word sequences in parallel, which is achieved through a mechanism known as self-attention. Self-attention enables models to understand the importance of each word from the input sequence while processing every word. For instance, in the sentence “the cat didn’t drink the milk because it was full”. In this sentence, “it” refers to “the cat” by attending to these words strongly.
The architecture of a transformer consists of:
- Input embeddings – Words are converted into numerical vectors that capture their semantic meaning.
- Positional encoding – They are added to provide information about the order of words in the sequence.
- Encoder – Processes the input sequence and creates a representation of its meaning.
- Decoder – Uses encoded representation to generate output sequence, word by word.
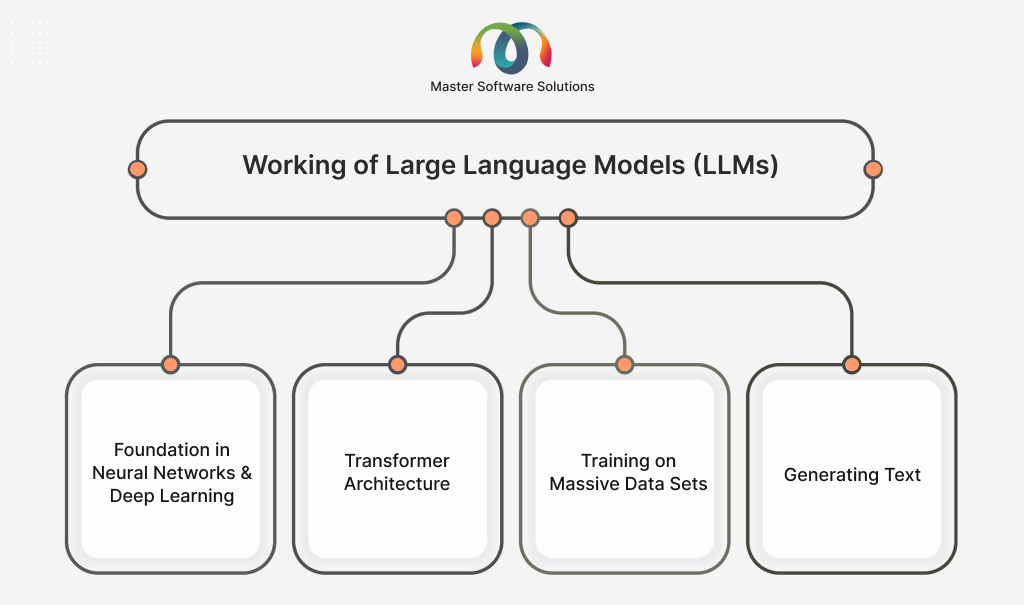
Training on massive data sets
LLMs are trained using large datasets that contain text from the internet, books, articles, and more. The LLM training process involves:
- Tokenization – The text is broken into smaller units, also known as tokens (words, parts of words, or individual characters).
- Self-supervised learning – The Model learns to predict missing words in a sentence or the next word in the sentence. This ensures that the model learns the underlying structure and patterns of language.
- Parameter tuning – When training the model, it adjusts its internal parameters to minimize the difference between its prediction and the actual text in the training data. It involves billions of parameters in large models.
Generating text
Once the model is trained, it can generate desired text based on the given prompt. This process includes:
- Input prompt – User provides an initial text or question.
- Contextual understanding – The model processes the input prompt, using its knowledge to understand context.
- Next word prediction – The model predicts the most likely word in the sequence, depending on the prompt and the preceding words it generated. This prediction is made based on the probabilities it learns during training.
- Iterative generation – The model continues to produce and append the next word, building output text step by step to a certain length or until a stopping condition is met.
Key capabilities
LLMs can gain various capabilities through this process, including:
- Text generation – Creating diverse forms of texts, including articles, stories, and code.
- Language translation – Converting text from one language to another.
- Text summarization – Briefing a long piece of content into shorter summaries.
- Question answering – Providing answers to the questions based on their knowledge.
- Conversational AI – engage in dialogue with users.
- Sentiment AI – Interpret the emotional tone of text.
Why are LLMs important?
Large language models are highly flexible and can perform varied tasks, including answering questions, summarizing documents, and completing sentences. Large language models show a great ability to make predictions based on little input. Here are some reasons that make LLMs important:
- LLMs enable computers to understand the complexities of human languages, leading to more intuitive and effective communication with AI systems to enhance human-computer interaction.
- LLMs can boost your productivity and automation through content generation, summarization, data analysis, and code generation.
- They facilitate access to information and knowledge by improving search engines, question answering, language translation, and making information understandable.
- These AI systems are widely helpful in healthcare, education, finance, and creative industries.
- They can help you offer a personalized customer experience with tailored content and recommendations based on their language and behavior.
Applications of LLMs
LLMs, such as OpenAI, BERT, and Gemini, can be used to develop various AI solutions across different domains. A few of them are:
Natural language understanding
LLMs make chatbots capable of engaging in natural conversation. They can comprehend the meaning, intent, and context of human language. They excel at tasks, including intent recognition, entity recognition, relationship extraction, question answering, and semantic search. It improves the accuracy and effectiveness of chatbots, virtual assistants, search engines, and information retrieval systems.
Content generation
They can automatically create various forms of content, including articles and blog posts, marketing copy, creative writing, technical documentation, and email drafting. This improves content creation efficiency, allows for personalization, and can overcome writer’s block.
Language translation
LLMs can understand multiple languages and convert text from one language to another fluently and accurately. This facilitates global communication, breaking linguistic barriers in education, business, and personal interactions, providing access to more knowledge.
Text summarization
They can write a long piece of writing that is shorter and easier to understand. LLMs can perform extractive summarization (select key sentences from the original text) and abstractive summarization (generate new sentences, conveying new ideas). This can help you save time processing a large amount of information, improve accessibility, and aid decision-making.
Sentiment analysis
LLMs can determine emotional tone or attitude in a piece of text. They can understand subtle sentiments through language, including sarcasm, irony, and complex sentences. These are crucial for understanding customer feedback, monitoring brand reputation, analyzing social media trends, and determining public opinions.
Conversational AI
Powerful LLM-based chatbots and virtual assistants can engage in more natural, context-aware, and multi-turn conversations.
Code generation
LLMs can generate code snippets, complete functions, write unit tests, and even translate between programming languages.
Question answering systems
Intelligent LLMs can answer complex questions based on large datasets of knowledge.
Information retrieval
They can enhance search engines and knowledge bases, providing more relevant and accurate results.
Personalized education
These large language models can help you create a custom learning experience and provide personalized feedback to students.
Healthcare
LLMs can assist you with medical diagnosis, drug discovery, patient communication, and medical literature analysis.
Financial modeling and analysis
They can extract insights from financial reports, analyze market trends, and generate financial narratives.
Training large language models
Large language models are transformer-based neural networks that contain multiple nodes and layers. Each node in a layer is connected to all the nodes in the subsequent layer and has a weight and a bias. Weights, biases, and embeddings are known as model parameters. Large neural networks can have billions of parameters. The more complex the task you want the LLM to perform, the more data you’ll have to train it with. The process of training an LLM is:
Pre-training
Pre-training is an initial stage where the LLM learns fundamental language skills such as grammar, syntax, and semantics. It includes feeding a large text dataset, using techniques like masked language modeling or next-word prediction.
Fine-tuning
This specializes the pre-trained model for a specific task or domain. Here, the model is trained using a smaller dataset of labeled data relevant to the task.
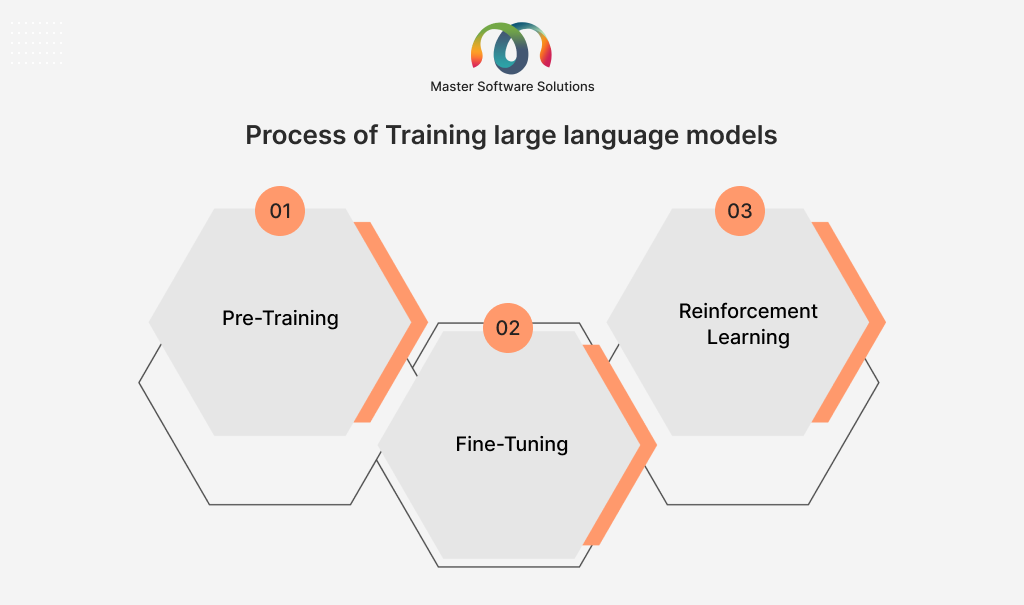
Reinforcement learning
It includes aligning LLM’s output with the desired qualities or preferences. The model is trained using user feedback and optimizes its results based on rewards or penalties.
How does Master Software Solutions help with LLMs?
Master Software Solutions provides AI agent development services for businesses that want to build their custom AI solutions. We leverage advanced large language models (LLMs) like OpenAI, Gemini, Gemma, DuckDB, Llama, and Mistral to develop advanced AI agents. We have developed 100+ turnkey AI solutions using these models. If you are interested in building such AI solutions, book a meeting to discuss your requirements.